Vision Language Model
Advanced multimodal AI that bridges visual data and language understanding, capable of analyzing images, interpreting scenes, and generating insightful text-based responses for applications in quality control, content moderation, and data extraction.
Client
AaladinAI (Internal)
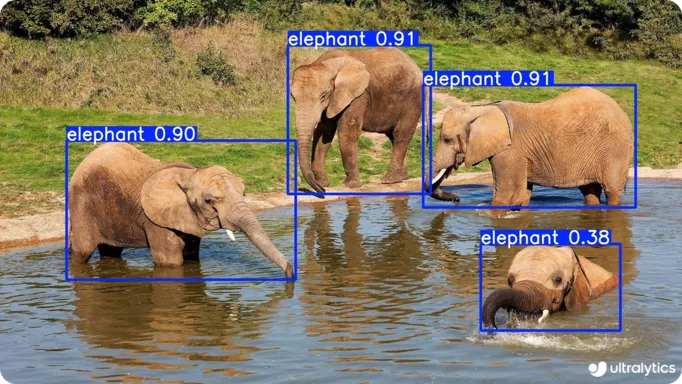
Project Screenshots
Visual overview of the project interface and key features

The Challenge
Businesses need to understand and interpret visual data in context with natural language.
Our Solution
Developed Vision Language Model that connects visual understanding with language processing for comprehensive multimodal intelligence.
Technologies Used
Key Features
 Image analysis and interpretation
Image analysis and interpretation- Scene understanding
- Text-based response generation
- Zero-shot segmentation
- Visual question answering
- Object localization
Results & Impact
Measurable outcomes and business impact achieved
91% accuracy in object recognition
Automated quality control capabilities
Enhanced content moderation
Improved data extraction accuracy
Our Office
Gulshan 1, Dhaka
13th Floor, Crystal Palace,
Gulshan 1, Dhaka, Bangladesh
Contact Info
Business Hours
Sun - Thu
9:00 AM - 6:00 PM PST